Understanding process mining
What is a process?
A process is a sequence of activities performed to achieve a goal. Whether formalized or not, every business performs processes.
Let’s take the example of a small take-out restaurant, Mary is the manager and the only employee. She takes orders and serves customers. A simplified process can be described as follows:
- Take the customer’s order
- Prepare the order
- Serve the customer
- Collect the customer’s payment
It can be represented simply:

restaurant process
To retain her customers, Mary decides to set up a loyalty card which gives a discount, in this case, the process becomes:
- Take the customer’s order
- Prepare the order
- Serve the customer
- Ask for the loyalty card
- If yes apply the discount
- Collect the customer’s payment
which is represented as follows:

restaurant process with discount
We see here that there can be variations in the process, not all activities are executed each time the process is executed.
Why study processes?
The previous example is very simple. In reality, companies have much more complex processes, with many activities and actors, as well as choices to be made according to different criteria.
The execution of the processes can be made complex by problems which require a reaction which diverges from what is usually done (for example, a component unavailable for production or a badly entered bank account number for invoicing) or by actors who don’t follow the process to the letter.
Processes evolve, for example for the launching of a new product or by integrating a new software.
But how do you know if the process is effective? Are there deviations that can impact the cost for the company or the quality of service for the customer? Did the last commercial campaign cause an overload of work for the accounts? Does it impact your revenue? How do you measure it?
You want more automation, but you want to automate a process that works, not automate tasks that are inherited from the past and that contribute to making the process complex.
Eventlog
The majority of companies work with an information system. Order taking is done using software, production is initiated in the system, as is invoicing.
Each activity gives rise to the recording of information, for example, the order number, the item ordered, the quantity. These are the transactions stored in the databases and that we are used to exploiting.
Each of its transactions corresponds to an event (create the order, modify the order), and contains information such as the date and time of the event, the person who carried it out.
By collecting all this information describing an event, relating to the process that we wish to study, we obtain an event log.
Let’s go back to the case of the restaurant, and suppose that Mary traces all the actions performed on her cash register. We therefore obtain an event log as follows:
| commande_id | activity_id | resource_id | timestamp |
|---|---|---|---|
| 1 | Take order | Mary | 2021-09-28 08:02:00 |
| 1 | Prepare order | Mary | 2021-09-28 08:05:10 |
| 1 | Server customer | Mary | 2021-09-28 08:06:39 |
| 1 | Take payment | Mary | 2021-09-28 08:09:40 |
| 2 | Take order | Mary | 2021-09-28 08:09:40 |
| 2 | Prepare order | Mary | 2021-09-28 08:12:29 |
| 2 | Server customer | Mary | 2021-09-28 08:13:54 |
| 2 | Take payment | Mary | 2021-09-28 08:17:01 |
| 3 | Take order | Mary | 2021-09-28 08:17:01 |
| 3 | Prepare order | Mary | 2021-09-28 08:20:28 |
Each row of the table represents an event, i.e. an action performed related to an activity. We distinguish an event from an activity because an event is unique (Mary performs this activity at 10:31 am) but an activity can be repeated (Mary has unfortunately applied the discount twice).
We can see that each line is referenced by the command number, this is the identifier of the process instance. It is thanks to this unique identifier that we can link the sequence of activities and recreate the execution of the process for this order.
From eventlog to process
How to use this volume of events to study the process?
This is the domain of process mining!
From these events, we can recreate the process as it happened, taking into account all the events. We can then map the process by visualizing all the activities of the process and the different routes, based on real data. A process map is then obtained.
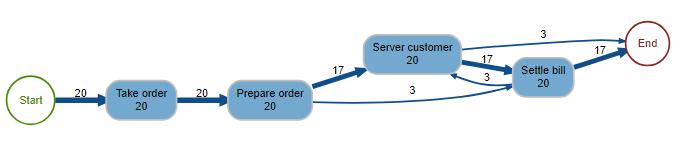
Process map 1
We expected the process of Figure 1, and we see that the reality is a little more complex. In 15% of cases, Mary does not follow her theoretical process and cashes in before serving the client.
We can look at the different traces left by the process, i.e. all the different sequences of activity that the process has taken, as well as their relative and cumulative frequencies:
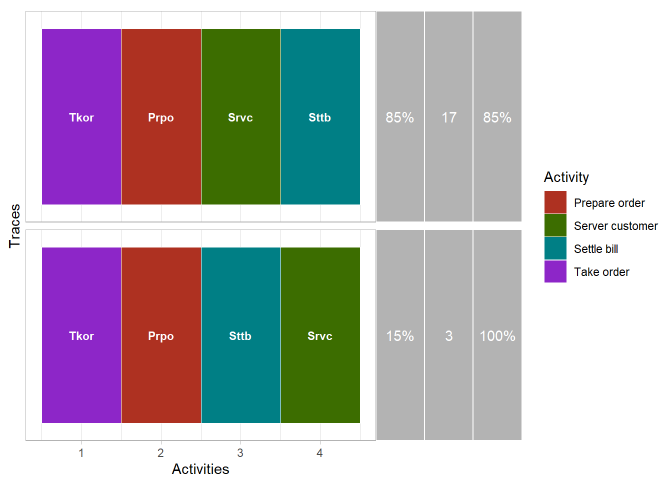
Traces of the first process
Now let’s take a look at what happens after Mary sets up her loyalty program. Starting from the eventlog for this period, we can display the map of the actual process:
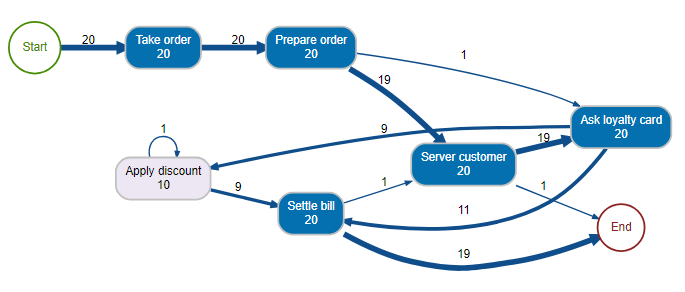
Process map 2
Here again, we are on a relatively simple process, and we can see that in reality there have been variations. Let’s see how the different routes are distributed:
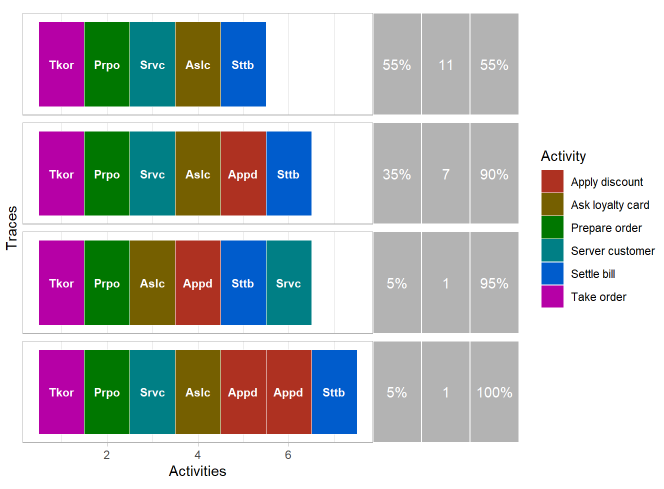
Traces of the second process
In 90% of the cases, the process corresponds to the theoretical process, but we can see two deviations, in particular, a case for which the discount was applied twice.
Process discovery
One of the functions of process mining is to discover the theoretical process from the event log. Usually, the modeling of an existing process is manual, and involves interviewing the various stakeholders. We then model a process based on what the actors have explained, which often results in an idealized theoretical process, which does not reflect reality.
One of the functions of process mining is to model the process from real data. Let’s look at the previous example including the loyalty card. We want to discover the theoretical process, so we will focus on the traces which represent 90% of the cases. The algorithm (here inductive miner) makes it possible to discover this process and to present it in a BPMN diagram. By running the algorithm on the previous eventlog, we then obtain the following theoretical process in BPMN format:

Automatic process discovery
The process discovered by the algorithm from the eventlog corresponds well to what we expected to find (equivalent to the process in figure 2).
Check Compliance
One of the concrete uses of what we have just seen is to automatically detect anomalies, and for example during the execution of a process to ensure that the case is in compliance with the theoretical process or to detect non-conformities.
For example, if we take the process that the algorithm discovered, we get the following Petri net below.

Petri Net
We can then “replay” the eventlog with the Petri net, and detect if there are missing or remaining tokens. All this is done automatically and we can only look at the summary and display the cases that have a problem:

Non-conformities detection
We find the two previous cases, but this time detected automatically:
- The first anomaly for case 30 is on the “Request loyalty card” activity. Indeed according to the theoretical process, it is the “Serve customer” activity that should have been carried out after the “Prepare order” activity.
- The second anomaly for case 40 is on the “Apply discount” activity, since this was actually performed twice according to the eventlog, whereas in theory it can only be performed once , or not at all.
This allows you to focus directly on the instances that are not compliant, which could not be done manually, on a process having thousands or hundreds of thousands of instances as is the case for most companies.
Go further
We have seen in a very simple case what a process is, an eventlog, and that it allows not only to visualize the actual execution of the process, from a process map, or from the different traces, but also from discover the theoretical process, and detect non-conformities.
In the reality of a company, the processes are much more complex than the example of the restaurant, with many actors, many activities which can take place in parallel or in series, and deal with thousands or millions of instances. Process mining then shows its power by providing many tools for the study of processes using existing data, that would not be possible with a traditional approach.
We have just seen that we can detect an instance that deviates from the theoretical process. But we can also have instances that respect the theoretical process, but take longer than normal, or loop over a series of activities, generating a longer delay for the customer and a greater additional cost for the company. So many cases that it is important to analyze and understand, and for which process mining is of great help.
Apart from detection for monitoring, support or auditing purposes, we can further use these data to make predictions and recommendations, for example by recognizing patterns that indicate that a deviation from an instance in progress is probable, which then makes it possible to intervene upstream or to anticipate actions to be taken.
To view and manipulate on an order to cash process, you can follow the link below. The demo includes additional elements, such as resource and performance analysis:
Click on the image to access the application (in a new tab because it is hosted on a different server).
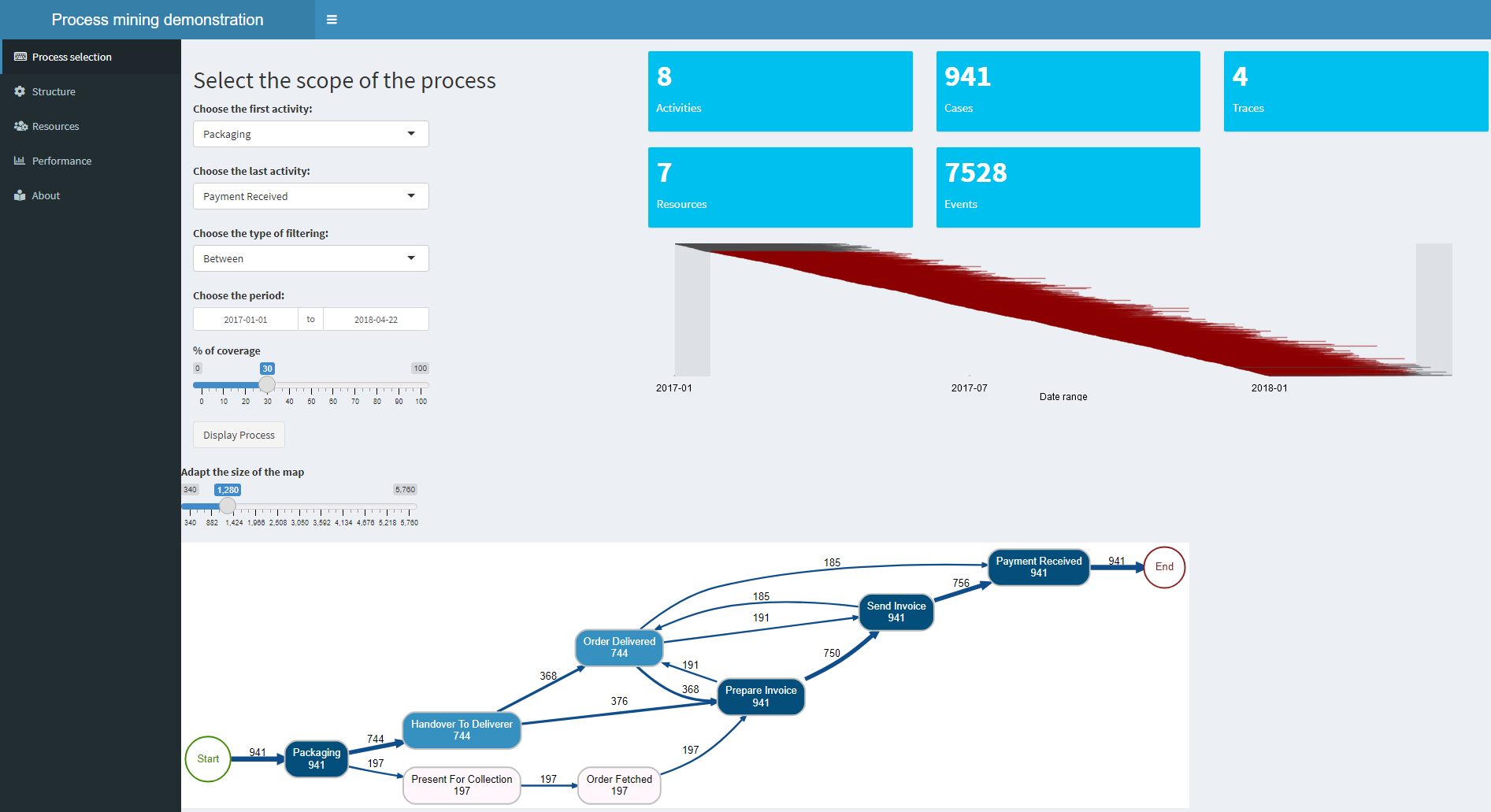
Useful links
Introduction to Process Mining and Demo: process mining demonstration
Concepts used in the article:
- Learn more about Petri nets: Wikipedia Petri nets
- The inductive mining algorithm: Wikipedia inductive miner
- BMPN modeling: Wikipedia BMPN and BMPN website
In practice :
Christophe Nicault
Information System Strategy
Digital Transformation
Data Science
I work on information system strategy, IT projects, and data science.